Challenge of Multi-modal Learning
1. 데이터의 표현 방법들이 모두 다름
ex) Audio, Image, Text를 데이터로 표현하면 이들은 다 제각각의 형태를 띔
2. 서로 다른 Modality에서 오는 정보량, feature spaces에 대한 특징들이 불균형함
ex) '아보카도 모양의 armchair' 라는 텍스트를 이미지로 변환하는 task를 수행할 때,
'아보카도 모양의 armchair'로 여러 이미지가 나올 수 있음( 1:N의 관계 )
3. 특정 Modality에 모델이 편향될 수 있음
ex) Action Recognition을 한다고 할 때,
노래를 부르는 Vedio는 Audio를 참조할 수 있겠지만
대부분의 행위는 Visual Data로 판단 가능하므로 Visual Data를 참조하는 모델에 편향될 수 있음
Patterns of Multi-modal Learning
Multi-modal Learning이 가진 어려움들에도 불구하고,
여러 감각 기관(Sensor)에서 오는 정보들을 취합하는 Multi-modal Learning은 중요한 문제로
Multi-model Learning을 수행하는 일정한 패턴은 다음과 같은 3가지가 존재한다.
1. Matching : 서로 다른 Modality를 공통된 space로 보내서 match
2. Translating : 하나의 Modality를 다른 Modality로 translate
3. Referencing : 하나의 Modality에서 같은 Modality로 출력을 낼 때, 다른 Modality를 reference

Multi-modal task (1) - Visual data & Text
1. Joint embedding (Matching)
Image Tagging
- 이미지가 주어졌을 때, Tag를 생성할 수도, 또는 Tag를 가지고 이미지를 찾을 수 있는 Application

Text, Image 각각에 pre-trained unimodal model들을 가지고J
같은 space를 공유할 수 있게 dimension이 같은 feature vector를 각각 뽑아낸다. ( Text, Image )
이 둘이 호환성을 가지도록 Joint embedding space를 학습
Joint embedding space에서 matching되는 pair는 거리가 가깝게,
mathcing되지 않는 pair는 거리를 멀리하면서 학습


Joint embedding을 학습하고 나면 analogy relationship까지 학습이 됨
ex) 개 사진에 'dog'이라는 embedding 정보를 빼고 'cat'이라는 정보를 입력하면
고양이 이미지는 물론 원본처럼 잔디밭이 배경인 사진이 검색됨

2. Cross Modal Translation (Translating)
(1) Image Captioning
- 이미지가 주어지면 그 이미지를 가장 잘 설명하는 Text를 생성하는 Application

Show and Tell
- Image Captioning의 한 방법
1. ImageNet에 Pre-trained된 CNN 모델을 Encoder로 사용하여 fixed dimensional vector로 바꿔줌
2. LSTM module을 Decoder로 사용하여 Encoder에서 넘어 온 vector를 condition으로 하여,
시작 토큰 S가 들어오면 output(단어)를 출력하고 이 과정을 종료 토큰이 나올 때까지 반복

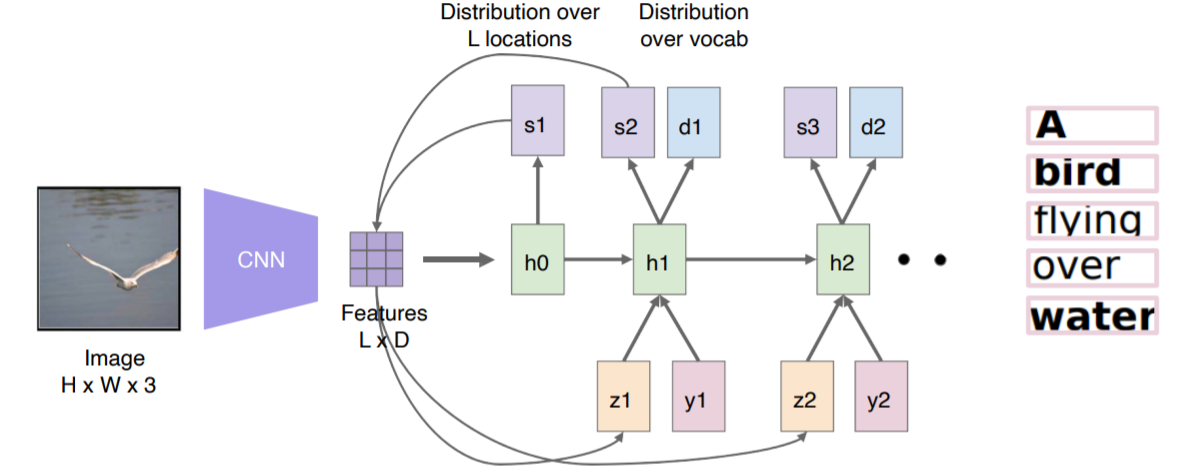
Show, Attend, and Tell
- Image Captioning의 한 방법
- Show and Tell이 하나의 fixed dimensional vector를 가지고 sentence를 추론했다면,
이 방법은 각 단어를 출력할 때 해당 부분을 보고 출력을 함
1. 이미지를 Input으로 집어넣으면
2. 하나의 fixed dimensional vector로 만드는 것이 아니라,
14x14의 공간정보를 유지하고 있는 feature map 형태로 출력
3. 이 feature map을 RNN에 넣어줌.
4. 이 RNN은 반복해서 하나의 단어를 출력할 때마다 feature map을 참조하면서 다음 단어 생성


사람이 얼굴 이미지를 보는 방식에서 고안한 방법이 Attention mechanism
Spatial한 feature( a )가 들어오면 RNN을 통과시켜서 어디를 참조해야하는지 heatmap( s )을 만들어줌
이 heatmap과 feature를 결합하여 z라는 벡터를 만들는데 이것을 Soft attention embedding이라 부름

Show, Attention, and Tell의 Inference 과정은 다음과 같다.
(2) Text to Image by genarative model
- 텍스트를 이미지로 변환할 경우에는 다양한 이미지가 생성될 수 있음
1. 텍스트를 fixed dimensional vector로 만들어주는 네트워크가 필요
2. fixed dimensional vector에 가우시안 랜덤 코드를 붙여 똑같은 Input에도 다양한 Output이 나오게 함
3. 생성된 이미지가 들어오면 spatial feature를 뽑고 여기에 sentence 정보를 줌으로써 True/False 판별

3. Cross Modal Reasoning
Visual question answering
- 영상이 주어지고 질문이 주어지면 답을 출력하는 Task
1. Image stream에서는 Pre-trained된 네트워크를 사용해서 fixed dimensional vector를 출력하고,
2. Question stream에서는 RNN으로 Encoding하여 fixed dimensional vector를 출력
3. 각 stream에서 출력한 fixed dimensional vector 2개를 point-wise multiplication하여
두 feature가 interation할 수 있게 만듦
4. 그리고 이것을 end-to-end 학습

'기술 > 딥러닝' 카테고리의 다른 글
| [Boostcamp AI Tech] 3D Understanding (0) | 2021.09.17 |
|---|---|
| [Boostcamp AI Tech] Computer Vision(1) (2) | 2021.09.10 |
| [Boostcamp AI Tech] Level1 P-Stage(1) (0) | 2021.08.27 |
| [Boostcamp AI Tech] PyTorch (0) | 2021.08.20 |
| [Boostcamp AI Tech] Sequential Model - Transformer (0) | 2021.08.15 |


