Transformer 구조는 기본적으로 Sequential Data를 다루는 하나의 방법론이다.
Sequential Data는 때때로 중간중간 값이 빠지거나 배치가 바뀔 수 있다.
( 대표적인 Sequential Data인 우리의 '언어'를 생각해보면 쉽다. )
따라서, RNN과 같이 입력이 Sequential하게 들어가는 모델들은
위와 같은 경우에 대해 모델링하는 데 어려움을 겪을 수 있다.
이 문제를 해결하기 위해 등장한 방법론이 오늘 정리할 Transformer이고,
Transformer는 self-attention이라는 구조를 사용하게 된다.

Transformer
Transformer는 동일한 구조를 갖지만
네트워크 파라미터가 다르게 학습되는 Encoder와 Decoder가 쌓여 있는 형태를 취한다.

하나의 Encoder는 Self-Attention과 Feed Forward Neural Network 2단으로 되어 있고,
여기서 Self-Attention이 Transformer가 좋은 성능을 가지게 된 아이디어라고 할 수 있다.

입력으로 n개의 embedding vector들이 들어오면 Self-Attention은
이 n개의 embedding vector들에 대응하는 n개의 vector를 뽑아낸다.
이 때 각 zi는 xi만을 고려하는 것이 아니라 나머지 n-1개의 x vector들도 고려한다.
그렇기 때문에 Self-Attention은 Dependency를 가진다.
반면 Feed Forward NN은 Dependency없이 들어오는 z를 변환해주는 작업만을 수행한다.

좀 더 자세히 들어가면 Self-Attention 구조는
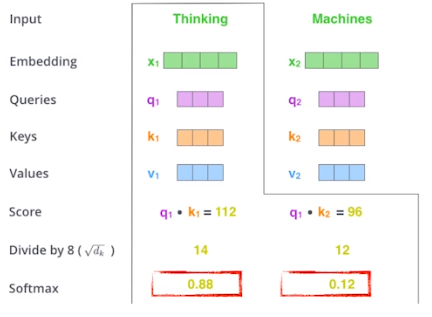
Query, Key, Value 3가지 벡터를 각각의 입력에 대해 만들어낸다.
그리고 이것들을 가지고 Score vector를 만들어 주는데
이 때 내가 encoding을 하고자 하는 vector ( 그림에서는 Thinking )와
나머지 n개의 단어의 Key Vector를 내적해줌으로써 계산한다.
이 Score vector는 encoding하려는 vector와 나머지 vector들의 유사도를 정하는 데 사용된다.
즉, encoding하려는 vector와 나머지 vector들 중
어떤 vector와 더 interaction이 일어나야 하는지를 표현한다고 할 수 있다.
Score vector를 구하고 나면, Normalization을 해주는데
이 때, Key vector 차원의 제곱근으로 Score vector를 나눠주는 방식을 취한다.
그 후, softmax를 취해 각 vector들간의 interaction에 대한 값(attention weight)을 얻게 된다.

Self-Attention에서 최종적으로 얻으려는 encoding vector z는
각 embedding vector의 attention weight와 Value vector를 weighted sum한 것이라고 할 수 있다.

여기서 주의할 점은 Query vector와 Key vector는 내적을 해야하기 때문에 항상 차원이 같아야 한다.
반면, Value vector는 차원이 달라도 상관없다.
그리고 최종적으로 encoding vector z는 Value vector의 차원과 같아진다.
z를 얻기까지의 계산을 간단하게 정리하면 결국 아래와 같다.

Transformer는 Input이 고정되어 있고 네트워크가 고정되어 있다 하더라도
encoding하려는 vector와 그 옆의 vector들이 달라짐에 따라서 encoding한 값이 달라지게 된다.
그렇기 때문에 훨씬 더 많은 것을 표현할 수 있는 특성을 가진다.
그러나 n개의 input을 처리한다고 한다면 Transformer는 n개의 input을 한번에 처리하게 되므로
n^2만큼의 computation cost를 가진다는 한계를 지닌다.
Multi-Head Attention
Mutli-Head Attention은 하나의 embedding vector에 대해
n개의 Query, Key, Value vector를 만들어 Self-Attention을 수행해
n개의 encoding 결과(z)를 만드는 작업을 뜻한다.
Encoder는 하나만 있는게 아니라 여러개 있기 때문에 입력과 출력의 차원을 맞춰줄 필요가 있다.
따라서 각각의 z를 concatenate하여 여기에 W를 곱해 출력의 차원을 맞춰준다.

또한, Encoder에 입력을 넣기 전 Positional Encoding이 추가되어야 한다
Self-Attention의 과정을 생각해보면 입력 데이터의 순서는 independent한 걸 알 수 있다.
따라서, Sequential Data의 순서 정보도 고려하기 위해 Positional Encoding을 더해준다.
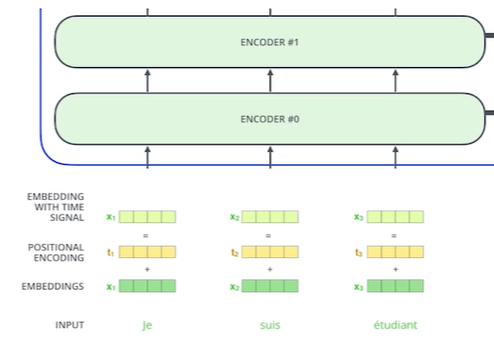
Self-Attention을 거치면 출력값에 Layer Normalization을 하고, Feed Forward하고
이런 작업을 계속 반복해서 수행하게 된다.

Encoder는 입력을 표현하는 부분이었다면
Decoder는 Encoder에서 넘어오는 값을 가지고 생성하는 부분이라 할 수 있다.
Input을 Decoder에 있는 출력하고자 하는 값으로 만드려면
Input에 해당하는 값들의 Encoder 최상단 Key, Value vector가 필요하고,
Decoder에 들어가는 만들어진 Query vector와
Encoder로부터 넘어오는 Key, Value vector를 가지고 최종 결과값을 만들어 내게 된다.
그리고 이 출력은 Autoregressive한 방식으로 만들어지게 된다.

학습 단계에서는 masking을 통해 이전 vector에는 dependent하게 만들고,
뒤에 vector에는 independent하게 만들어 미래 정보를 활용하지 않게 한다.
Encoder-Decoder Attention Layer가
위에서 살펴본 Encoder와 Decoder간의 interaction이 일어나는 곳으로,
지금까지 Decoder에 들어간 단어로 Query를 만들고,
Key, Value는 Input이 Encoder를 거쳐 나온 것으로 활용하게 된다.

References
다 함께 배우고 성장하는 부스트코스
부스트코스(boostcourse)는 모두 함께 배우고 성장하는 비영리 SW 온라인 플랫폼입니다.
www.boostcourse.org
https://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Chinese (Simplified), French, Japanese, Korean, Russian, Spanish, Vietnamese Watch: MIT’s Deep Learning State of the Art lecture referencing
jalammar.github.io
'기술 > 딥러닝' 카테고리의 다른 글
| [Boostcamp AI Tech] Level1 P-Stage(1) (0) | 2021.08.27 |
|---|---|
| [Boostcamp AI Tech] PyTorch (0) | 2021.08.20 |
| [Boostcamp AI Tech] RNN (Recurrent Neural Network) (0) | 2021.08.15 |
| [Boostcamp AI Tech] CNN (Convolutional Neural Network) (0) | 2021.08.14 |
| [Boostcamp AI Tech] Optimization (0) | 2021.08.11 |


