Optimization의 중요 개념
1) Generalization (일반화)
입력 데이터가 학습 데이터와 달라도 출력에 대한 성능 차이가 나지 않도록 하는 것을 Generalization라 함
일반적으로 학습을 진행하면서 특정 시점이 지나면 Training error는 감소하고,
Test error는 오히려 증가하면서 모델의 성능이 떨어짐
Generalization Performance는 Training error와 Test error의 차이( Generalization gap)를 의미하며,
이 차이가 적을수록 네트워크의 성능이 학습데이터와 비슷할 거라고 보장해 줌

2) Overfitting (과대적합), Underfitting (과소적합)
- Overfitting
학습데이터에 대해 과하게 학습하여 학습데이터에 대해서는 잘 동작하지만
평가데이터에 대해서는 잘 동작하지 않는 상황을 의미
모델 복잡도가 커서 학습데이터를 외워버리면 이러한 상황이 발생
- Underfitting
학습데이터에 대해서도 잘 동작을 하지 못하는 상황
학습 횟수가 너무 적거나 모델이 너무 단순하여 발생
3) Cross-validation (교차검증)
모델이 독립적인 평가데이터에 얼마나 잘 일반화될지 평가하는 모델 검증 기법
학습데이터로 학습시킨 모델이 학습에 사용되지 않은 검증데이터 기준으로 얼마나 성능이 나오는지 확인
데이터의 모든 부분을 사용하여 모델을 검증하며, 여러 번의 검증결과를 종합하여 모델의 예측 성능을 추정
4) Bias and Variance (편향과 분산)
Bias 출력을 평균적으로 봤을 때 이것들이 Target에 얼마나 접근하게 되는지를 의미
(Bias가 낮을수록 출력이 평균적으로 Target에 근접하고, 높을수록 Target에서 멀어짐 )
Variance 입력을 넣었을 때 출력이 얼마나 일관적으로 나오는지를 의미
(Variance가 낮을수록 일관된 출력을, 높을수록 출력이 달라짐)

Bias and Variance Tradeoff
학습데이터에 noise가 있을 경우, cost를 최소화하는 것은 bias, variance, noise를 최소화는 것을 의미
그러나, bias와 variance는 tradeoff 관계에 있기 때문에 두 개를 동시에 줄이는 것에는 한계가 있음

5) Bootstrapping
학습 데이터를 random sampling하여 여러 학습데이터, 여러 모델을 만들어 사용하는 작업을 의미
6) Bagging, Boosting
- Bagging (Boostrapping aggregating)
Boostrapping을 하여 여러 모델을 만들어 그 결과값들의 평균을 내는 작업, 일반적인 Ensemble
- Boosting
weak learner들을 sequencial하게 합쳐서 하나의 strong learner를 만드는 방법

Gradient Descent Methods
Batch-size Matters
배치 사이즈가 클수록 Sharp Minimum에, 배치 사이즈가 작을수록 Flat Minimum 도달
Flat Minimum을 보면 Generalization gap이 낮은 것을 알 수 있음
반면, Sharp Minimum은 Generalization gap이 상대적으로 큼
즉, 일반적으로 배치 사이즈를 줄일수록 Flat Minimum에 도달하므로 배치 사이즈가 낮을 때 학습 성능이 좋음

1. SGD
W에 Learing rate와 Gradient의 곱을 빼주는 기본적인 Gradient Descent
적절한 Learning rate를 설정해주는 것이 중요하면서 또 어려움

2. Momentum
이전 배치의 방향 정보를 활용해보자는 아이디어에서 시작
momentum과 현재 gradient를 합치 accumulation을 가지고 gradient를 업데이트
이전 배치의 방향 정보를 가지기 때문에 gradient가 많이 왔다갔다하더라도 잘 학습을 할 수 있음

3. Nesterov Accelerated Gradient (NAG)
momentum이 현재 주어진 gradient 정보를 가지고 accumulation을 계산했다면,
Nesterov Accelerated Gradient는 Lookahead gradient라는 것을 활용하여 accumulation를 계산
이 Lookahead gradient는 현재 정보가 주어질 때 가지고 있던 정보 방향대로 가보고
그 위치에서 gradient를 계산한 것을 가지고 accumulation 계산
NAG는 Momentum보다 Local minima에 조금 더 빨리 수렴할 수 있는 장점이 있음
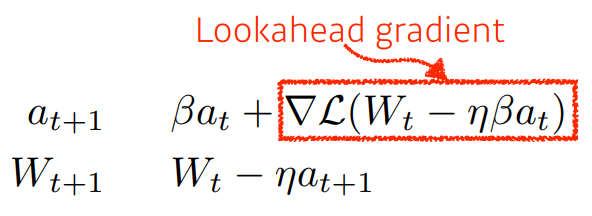

4. Adagrad
그동안 변화량이 적은 파라미터들은 크게 변화시키고 변화량이 큰 파라미터는 적게 변화시킴
그동안의 변화량 정보를 가지고 있는게 아래 수식의 Gt에 해당
그러나, 이 Gt가 계속 커지게 되면 0으로 수렴하면서 더 이상 Gradient 업데이트가 안될 수 있음

5. Adadelta
Adagrad에서 Gt가 커져서 gradient가 업데이트 안되는 문제를 최대한 막기 위해 등장
현재 timestep t가 있을 때, window 사이즈만큼 gt 값을 들고 있으면 되지 않을까라는 아이디어에서 출발
EMA(Exponential Moving Average)를 통해 Gt를 업데이트
Learning rate가 따로 없다는 점이 Adadelta의 가장 큰 특징

6. RMSprop
Adagrad의 Gt 자리에 EMA를 통해 구한 Gt를 넣어줌으로써 수행

7. Adam
Momentum과 Adaptive Learning rate를 결합한 방법

Regularizaiton (규제)
1. Early Stopping
학습을 진행하면서 특정 시점이 지나면 Training error는 감소하고,
Test error는 오히려 증가하면서 모델의 성능이 떨어짐.
따라서, Validation error를 활용하여 학습을 조기에 종료
2. Parameter Norm Penalty
네트워크 파라미터가 너무 커지지 않도록 네트워크 파라미터 수치들을 줄여주는 작업
Parameter Norm Penalty는 Weight Decay로 부르기도 함

3. Data Augmentation
딥러닝에서는 데이터의 양이 무엇보다 가장 중요
label이 바뀌지 않는 한도에서 주어진 데이터의 변형을 통해 데이터의 양을 늘리는 작업
4. Noise Robustness
입력데이터 또는 Weight에 Random Noise를 집어넣음으로써 모델 성능 향상 도모
5. Label Smoothing
두 개의 데이터를 뽑아서 섞어주는 작업, 결정경계를 부드럽게 만들어주는 작업
Mixup, Cutout, CutMix 등의 방법이 있음

6. Dropout
신경망 사이의 관계를 랜덤하게 일정 비율로 끊어줌으로써 강건한 feature들이 남을 수 있도록 해주는 작업
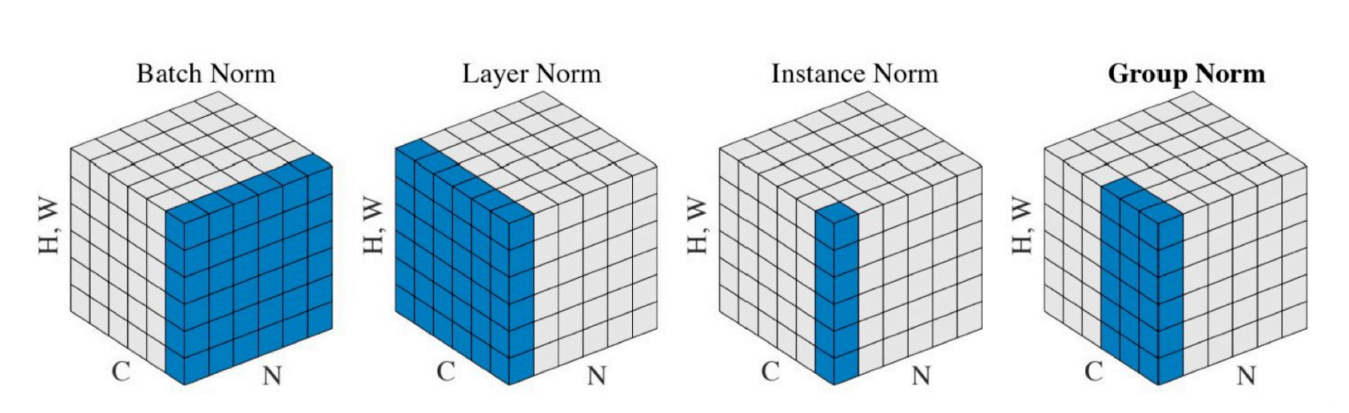
7. Batch Normalization
Batch Normalization을 적용하려는 Layer의 Normalization을 수행
Normalization에는 BN말고도 다양한 Normalization이 존재
'기술 > 딥러닝' 카테고리의 다른 글
| [Boostcamp AI Tech] RNN (Recurrent Neural Network) (0) | 2021.08.15 |
|---|---|
| [Boostcamp AI Tech] CNN (Convolutional Neural Network) (1) | 2021.08.14 |
| [Boostcamp AI Tech] Historical Review of Deep Learning (0) | 2021.08.09 |
| [Boostcamp AI Tech] 1주차 학습정리 (1) | 2021.08.06 |
| [Deep Learning] CS231n - 2. Image Classification (0) | 2021.07.01 |


