Convolution
Convolution 연산은 Kernel/Filter가 Image위를 이동하면서
Element-wise product를 수행한 후 모두 더해주면서 값을 얻어낸다.

32x32x3 image가 입력으로 들어오고, 5x5x3 filter가 4장 있다면 28x28x4의 feature map이 출력된다.
이처럼 입력 사이즈를 알고 filter의 사이즈와 개수를 안다면 출력의 사이즈를 계산할 수 있다.
또한 입력 사이즈와 출력 사이즈를 안다면 filter 사이즈와 개수를 계산할 수도 있다.
그리고 이 때 feature map을 얻기 위해 필요한 파라미터의 수는
4x5x5x3으로 filter의 사이즈와 개수의 곱으로 이해할 수 있다.

CNN은 Convolution Layer, Pooling Layer, Fully-Connected Layer로 구성되는데,
Convolution Layer와 Pooling Layer로 feature extraction을 수행하고, FC layer에서 분류를 수행한다.

추가적으로 filter가 이동하는 간격을 Stride라고 한다.
또한 Convoultion 연산을 하게 되면 입력 사이즈를 boundary information이 버려지게 된다.
따라서, 이 boundary information도 고려하고자 0값을 채워주는 Padding을 넣어주기도 한다.
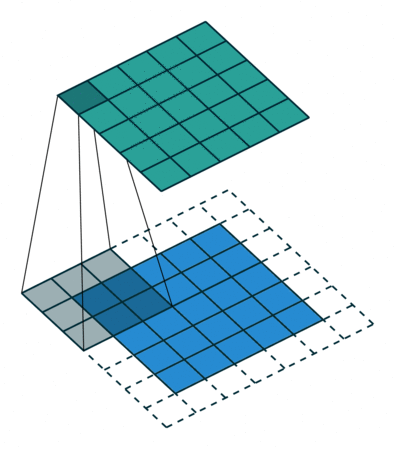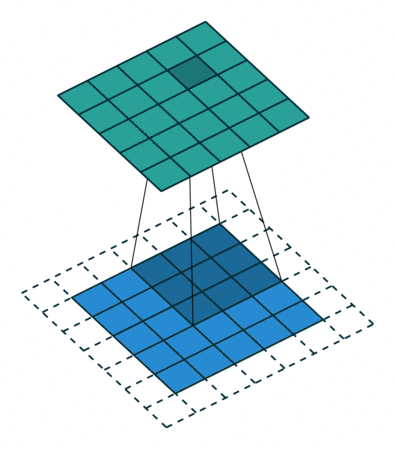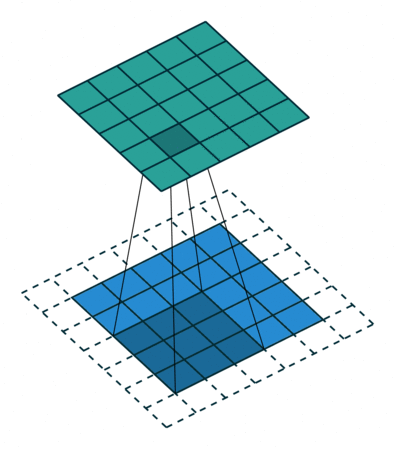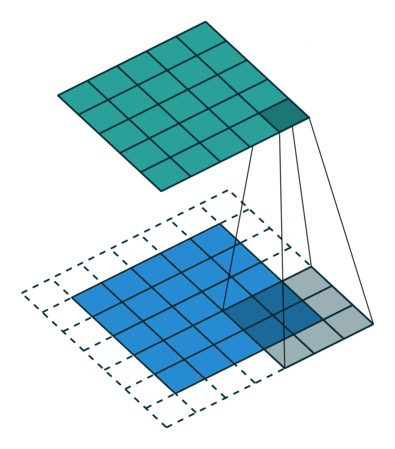
1x1 Convolution은 이미지에서 어떤 영역을 보지 않지만 채널을 줄여주는 역할을 수행한다.
이로 인해 Network의 Depth를 깊게 쌓으면서 동시에 파라미터 숫자를 줄일 수 있다.
대표적으로 bottleneck architecture에서 이런 1x1 Convolution이 사용된다.

ILSVRC 수상 Network
ILSVRC란?
ImageNet Large-Scale Visual Recognition Challenge의 준말로, 백만장이 넘는 이미지 데이터를 가지고
Classfication, Detection, Localization, Segmentation의 task를 수행하며 겨루는 대회이다.
AlexNet (2012)
Key Ideas
- Activation Fucntion으로 Relu (Rectified Linear Unit) 함수를 사용
- GPU 활용
- Local Response Normalizaion, Overlapping Pooling 사용
- Data Augmentation 사용
- Dropout 사용

VGGNet (2014)
Key Ideas
- 3x3 filter들만을 사용해서 depth를 깊게 쌓았음
- FC Layer에 대해 1x1 convolution을 사용
- Dropout 사용
- Layer 개수에 따라 VGG16, VGG19로 분류
VGGNet에서 특히 주목할만한 점은 3x3 fliter로 depth를 깊게 쌓은 점이다.
3x3 filter를 사용해서 2번의 convolution을 하게 되면
5x5 filter를 사용해서 1번의 convolution을 한 것과 동일한 Receptive field를 고려할 수 있다.
하지만 각각의 parameter의 수는 아래와 같이 달라지게 된다.
따라서, 더 적은 parameter로 depth를 깊게 쌓을 수 있는 것이다.

GoogLeNet (2014)
Key Ideas
- Inception block들을 잘 활용하여 Network in Network (NIN) 구조를 형성

Inception block
하나의 입력에 대해 여러개의 Receptive field 갖는 filter를 거치고,
여러 개의 response를 concatenation하는 효과를 지님
또한, 1x1 convolution이 중간에 추가로 들어가면서
channel-wise deimesion reduction이 되고, 파라미터의 수가 줄어드는 효과를 가짐

1x1 Convolution을 중간에 넣게 되면 1x1 Convolution이 없을 때와 같은 Receptive field를 가지고,
입출력 채널 역시 같음에도 파라미터 수가 크게 줄어드는 효과를 볼 수 있음

ResNet (2015)
Key Ideas
- Idetity map 추가 (skip connection)
- Bottleneck Architecture
Idetity map
입력 x를 출력값 f(x)에 더해주는 skip connection을 함으로써 residual만 학습하게 유도한다.

skip connection을 할 때 x와 f(x)의 사이즈를 맞춰주기 위해
1x1 Convolution을 하기도 하는데, 이것을 Projected Shortcut이라고 한다.
ResNet의 경우, Convolution Layer 뒤에 Batch Normalization을 놨는데,
Batch Normalization과 Activation Function의 순서는 논쟁거리 중 하나이다.

Bottleneck Architecture
Convolution을 하기전에 input channel을 줄이면서 파라미터 수를 줄이고
Convolution 후, input channel로 다시 늘리기 위해 Convolution 앞뒤에 1x1 Convolution Layer 배치

DenseNet (2017)
Key Ideas
- Concatenation
ResNet이 입력 x와, 입력 x가 B를 거쳐 나온 f(x)를 더해줬다면
DenNet은 x와 f(x)를 Concatenation하여 channel을 Dense하게 만든다.

그러나 Concatenation을 하게 되면 channel이 기하급수적으로 커지게 되고
파라미터의 수 역시 따라 커지게 되는 문제가 발생하게 된다.
따라서, 이를 해결하기 위해 중간중간 Transition Block을 두어 channel을 줄여준다.
Transition Block은 Batch Nomalization, 1x1 Convolution, 2x2 Average Pooling으로 구성되어 있다.

Semantic Segmentation
Semantic Segmentation 문제는 이미지의 모든 픽셀이 어떤 Label에 속하는지를 판별하는 문제이다.
아래의 사진을 보면 픽셀 영역별로 Person, Bicycle, Background가 나눠진 걸 확인할 수 있다.

Semantic Segmentation에 접근하기 위해 Fully Convolutional Network (FCN)에 대한 이해가 필요하다.
지금까지 해왔던 CNN은 Convolution을 거쳐 Flat하게 만든 후 Dense Layer를 연결하는 방식이였다.
그러나 FCN은 Flatten - Dense Layer 연결 대신 Convolution Layer를 연결해 output을 낸다.

CNN을 FCN으로 만들어 주는 Convolutionalization을 하게 되면
FC-Layer를 연결했던 기존 방식과 파라미터 수도 같고 사실 크게 달라지는 점은 존재하지 않는다.
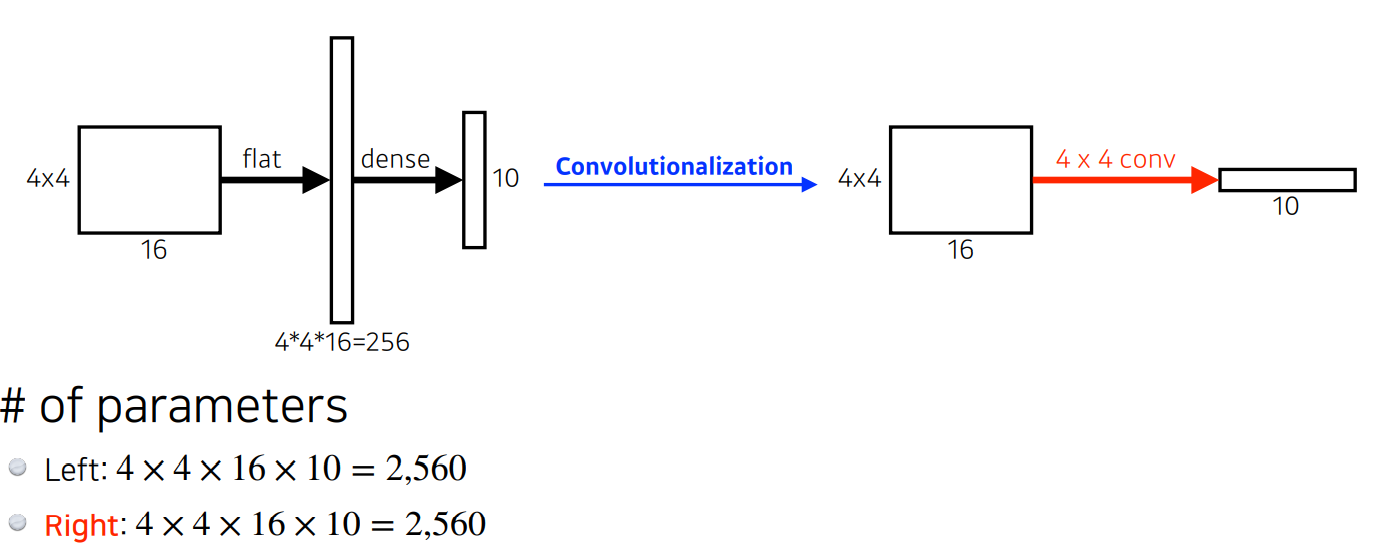
그러나 FCN으로 변경하면 입력 이미지에 상관없이 연산이 가능하다는 특징이 있다.
예를 들어 FC-Layer가 있던 기존의 구조는 FC-Layer 연결을 위해
reshape가 있었기 때문에 연산이 불가능하다.
하지만, Convolution이 가진 Shared Parameter 성질로 인해 ( filter size가 같은) FCN은 동작한다.
물론 출력으로 나오는 Spatial Dimension은 입력 이미지보다 훨씬 줄어들어 조잡하지만
마치 heatmap과 같은 효과가 있게 된다.

그리고 이 출력으로 나온 조잡한 Spatial Dimension을
원래의 Dense pixel로 늘릴 수 있는 방법이 고안됐고 그 방법으로 Deconvolution이 있다.
Deconvolution은 Covolution Transpose라고도 하며,
Convolution의 역연산으로 Spatial Dimension을 늘려준다.
그러나 엄밀하게 얘기하면 Convolution의 역연산은 존재할 수 없다. ( + 연산의 역이 없음을 떠올리면 쉽다.)
( 단순히 파라미터 계산의 용이성을 위해 역연산이라고 생각하겠다. )


이렇게 FCN을 만들고 per pixel classification을 수행하면 다음과 같은 결과를 만들어 낸다.

Detection
대표적인 Detection 방법으로 다음과 같은 것들이 있다.
R-CNN
R-CNN은 다음과 같은 순서로 작동한다.
1. 입력 이미지가 들어오면
2. 약 2000개의 region을 뽑아낸다.
3. AlexNet을 사용하여 각 region의 특징들을 계산하고
4. linear SVM을 이용해 classification을 수행한다.

SPPNet
R-CNN의 가장 큰 단점이라면 약 2000개의 region을 뽑았을 때,
이 각각의 region에 대해 CNN을 약 2000번 돌려야 한다는 것이다.
SPPNet은 이미지 내에서 bounding box를 뽑고 이미지 전체에 대해 feature map을 만든 다음,
bounding box에 해당하는 feature map의 tensor만 가져옴으로써 CNN을 한번만 수행한다.
Fast R-CNN
Fast R-CNN 역시 SPPNet과 컨셉은 비슷하다.
Fast R-CNN은 다음과 같은 순서로 작동한다.
- 이미지가 들어오면 bounding box들을 뽑아낸다.
- 그리고 이미지 전체에 대해 feature map을 생성하고,
- 각 bounding box에 대해 ROI pooling으로부터 고정된 길이의 feature를 가져온다.
- 그리고 이 feature를 가지고 Neural Network를 통과해 bounding box regressor와 class를 찾게 된다.
Faster R-CNN
Faster R-CNN은 bounding box를 뽑아내는 Region Proposal도 학습을 하자는 아이디어에서 출발한다.
이 Region Proposal을 학습하는 Network를 Region Proposal Network (RPN)이라 하며,
Faster R-CNN은 RPN과 Fast R-CNN을 결합한 모델이라고 할 수 있다.
RPN은 region에 물체가 있을지 없을지를 찾아주는 역할을 한다.
이 때, 필요한게 anchor box인데 이 anchor box는 미리 정해놓은 bouding box의 크기라 할 수 있다.
RPN 역시 FCN이 활용되고, output은 다음과 같은 이유로 9*(4+2)의 출력 channel을 가진다.

YOLO
YOLO는 동시에 bounding box들과 class probability들을 한번에 예측하기 때문에 빠른 속도를 자랑한다.
YOLO는 이미지가 주어지면 SxS grid로 이미지를 나눈다.
찾고 싶은 Object의 중앙이 해당 grid 안에 들어가면
해당 grid cell이 Object의 bouding box와 class probability를 같이 예측한다.

References
다 함께 배우고 성장하는 부스트코스
부스트코스(boostcourse)는 모두 함께 배우고 성장하는 비영리 SW 온라인 플랫폼입니다.
www.boostcourse.org
https://www.analyticsvidhya.com/blog/2021/05/convolutional-neural-networks-cnn/
Introduction to Convolutional Neural Networks (CNN)
Over the years CNNs have become a very important part of many Computer Vision applications. So let’s take a look at the workings of CNN
www.analyticsvidhya.com
ILSVRC 대회 (이미지넷 이미지 인식 대회) 역대 우승 알고리즘들
ILSVRC은 ImageNet Large Scale Visual Recognition Challenge의 약자로 이미지 인식(image recognition) 경진대회이다. 여기서 이미지 인식과 이미지 분류(image classification)는 같은 의미를 갖는다. 대용량..
bskyvision.com
https://towardsdatascience.com/types-of-convolutions-in-deep-learning-717013397f4d
An Introduction to different Types of Convolutions in Deep Learning
Let me give you a quick overview of different types of convolutions and what their benefits are. For the sake of simplicity, I’m focussing…
towardsdatascience.com
'기술 > 딥러닝' 카테고리의 다른 글
| [Boostcamp AI Tech] Sequential Model - Transformer (1) | 2021.08.15 |
|---|---|
| [Boostcamp AI Tech] RNN (Recurrent Neural Network) (0) | 2021.08.15 |
| [Boostcamp AI Tech] Optimization (0) | 2021.08.11 |
| [Boostcamp AI Tech] Historical Review of Deep Learning (0) | 2021.08.09 |
| [Boostcamp AI Tech] 1주차 학습정리 (1) | 2021.08.06 |


