들어가며
이번 여름에 기초 개념을 탄탄히 다져볼 겸 Stanford University의 유명 AI 강의인
CS231n 강의를 듣고 정리해 보기로 했다.
video로 공개된 강의가 2017년이 마지막이라는 점은 아쉽지만 아쉬운 대로 배워야지..
Lecture 1은 Introduction이라 바로 Lecture 2 - Image Classification부터 들어가겠다.
출처
Syllabus
http://cs231n.stanford.edu/2017/syllabus.html
Lecture
https://www.youtube.com/watch?v=OoUX-nOEjG0&list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv
Lecture Notes
https://cs231n.github.io/classification/
https://cs231n.github.io/linear-classify/
이 글에 있는 대부분의 이미지는 Syllabus에 올려진 강의 슬라이드와 강의 노트에서 가져온 것임을 밝힙니다.
Image Classification
Image Classification은 Computer Vision의 Core Task라고 할 수 있다.
컴퓨터가 특정 이미지를 받게 되고,
이 이미지를 사전에 정의된 여러 클래스 중에서 분류해내는 작업이 Image Classification이다.
단순하게 생각하면 이는 매우 간단한 작업이라고 생각할 수 있지만
컴퓨터는 이미지를 사람과는 다르게 본다.

위 슬라이드를 보면 알 수 있듯이 컴퓨터는 RGB(3 channels)를 각각 나타내는
800 x 600의 픽셀들로 이미지를 바라본다.
Image Classification은 또한 다음과 같은 어려움들을 가지고 있다.
- Viewpoint variation : 여러 카메라 관점에 따라 픽셀값들은 달라진다.
- Illumination : 조명은 픽셀에 영향을 미친다.
- Scale variation : 실제 크기와 이미지 크기는 다를 수 있다.
- Deformation : Object는 여러 자세를 취할 수 있다.
- Background clutter : Object가 배경에 섞여 식별하기 어려울 수 있다.
- Occlusion : Object가 어떤 물체에 가려지거나 숨을 수 있다.
- Intra-class variation : 같은 class내에서도 여러 가지가 존재한다.

그간의 시도
기존에는 모든 edges, corners, boundaries를 찾고, 규칙을 정해 Classification을 했다.
그러나, 이러한 접근 방법은 좋은 방법이 아니었는데
그 이유로는 첫째로, super brittle (다루기 힘들었고), 두번째로는 not scalable (확장 가능성이 떨어졌다.)

Data-Driven Approach
규칙을 정해 클래스마다 일일이 작성하는 방법이 아닌
머신러닝을 이용한 Data-Driven Approach를 사용하기 시작했다.
▶ 예를 들어, 기존 방식대로 고양이를 판별하려면
뾰족한 삼각형을 2개(귀) + ... + Corner가 연달아 3개 이상(발) = 고양이
이런 식으로 규칙을 작성해야 했다.
Data-Driven Approach는 다음의 단계로 구현된다.
1. 많은 이미지와 이미지에 매칭되는 Label들을 수집
2. 머신러닝을 사용해 분류기를 학습
3. 새로운 이미지로 이 분류기를 평가
Nearest Neighbor
가장 단순하게 Image Classification을 할 수 있는 방법으로 Nearest Neighbor가 있다.
Nearest Neighbor는 모든 이미지와 label들을 기억한 후,
예측 과정에서 훈련 데이터와 가장 유사한 label을 결괏값으로 출력한다.

Nearest Neighbor는 픽셀간의 거리 값을 판단 근거로 삼는다.
아래는 L1 Distance (맨해튼 거리)로 계산했을 때의 계산 과정이다.

Nearest Neighbor의 시간복잡도는
데이터를 기억만 하면 되므로 Train의 경우 O(1)이다.
반면, Predict의 경우 가장 유사한 데이터를 전체 훈련데이터 사이에서 찾아야 하므로 O(N) 이다.
분류기는 일반적으로 훈련과정보다는 예측 과정에서 빠르기를 원하기 때문에 이것은 큰 단점으로 작용한다.
K-Nearest Neighbor
K-Nearest Neighbor는 K개의 최근접 이웃들로부터 다수결을 통해 예측하는 모델이다.
K가 증가할수록 각 class의 경계는 smooth해진다.

Distance Matric으로는 L1 Distance 외에도 L2 Distance (유클리디안 거리)가 존재한다.
최근접 이웃의 개수 K와 같이 일종의 hyperparameter로 사용할 수 있다.

hyperparameter 설정 방법은
문제에 따라 최적의 hyperparameter가 다르므로 가장 성능 좋은 값들을 찾아야 하고,
그러기 위해 여러 번의 학습을 통해 성능을 측정해야 한다.
그러려면 데이터를 train, validation, test 목적에 맞게 아래와 같이 나눠야 한다.

아래 슬라이드처럼 여러 개의 fold로 나눠 나눈 개수만큼 학습을 수행하는 Cross-Validation 방법이 있다.
Cross-Validation은 딥러닝이 대량의 데이터를 다루고
또 많은 컴퓨팅 파워를 요구한다는 점에서 일반적으로 자주 사용되지는 않는다.

다시 돌아와 데이터를 train, validation, test로 나눠
hyperparameter들을 조정하고 K-Nearest Neighbor를 만들 수 있지만
K-Nearest Neighbor는 이미지에는 절대 사용되지 않는다.
그 이유는 아래와 같다
- prediction에서 시간이 너무 느리다.
- Distance Metric은 픽셀에서 크게 정보를 주지 않는다.
- 차원의 저주 문제
아래 슬라이드에서 확인할 수 있듯 L2 Distance의 경우
원본 이미지에 박스를 씌우거나 픽셀을 움직이거나 혹은 색의 농담을 변경해도
L2 Distance는 원본 이미지와 똑같다고 판단해 버린다.

또한, K-Nearest Neighbor는 Curse of dimensionality (차원의 저주) 문제를 겪는다.
차원의 저주란 차원이 커질수록 성능이 떨어지는 문제로
KNN에서는 고차원 공간에서 데이터 사이의 거리가 멀어지면서 발생한다.
K-Nearest Neighbor는 최근접한 이웃들로 판별을 하지만
실제로 그 이웃들은 아주 멀리 떨어진 데이터일 수 있기 때문에 설명력이 떨어질 수 있다.

Linear Classification
Linear classifer는 신경망의 기본이 되는 모델로 Parametric Approach 방식의 모델이다.
Parametric Approach란 모델의 가중치를 학습하는 방법으로,
전체 데이터를 저장하고 비교하는 K-Nearest Neighbor 방식과는 다르게
가중치 학습을 통해 빠르게 예측을 수행할 수 있는 방식이다.
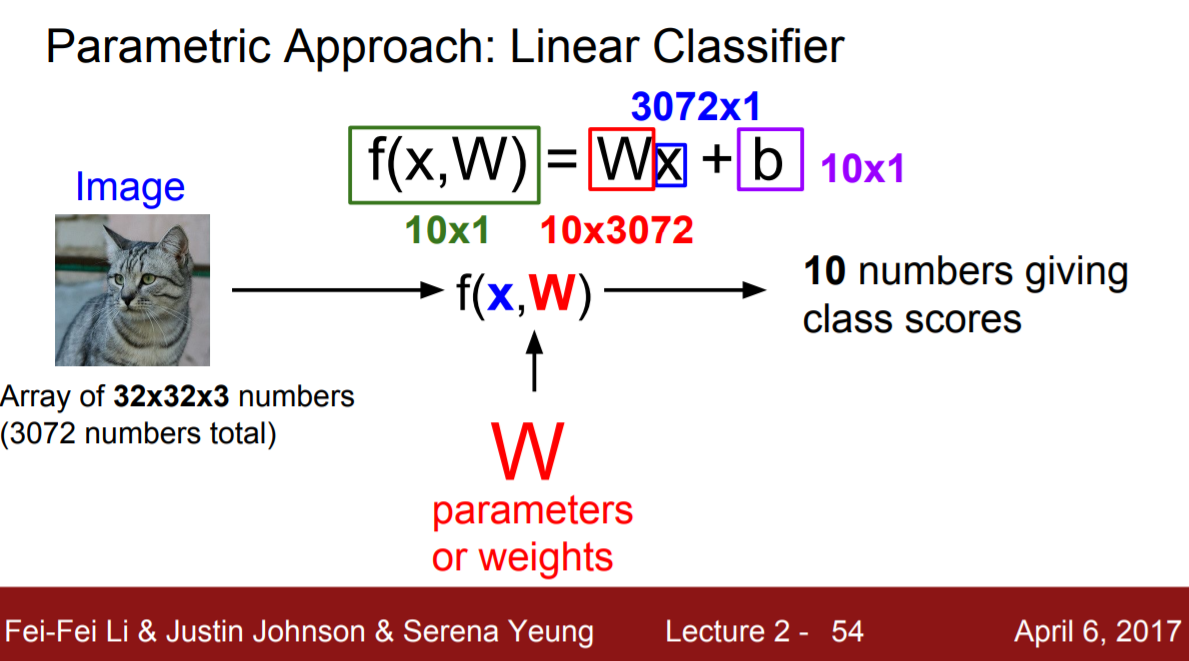
슬라이드를 통해 이해해보자.
입력으로 들어오는 고양이 이미지를 X라고 한다면,
weight (가중치)로 부르는 W와의 관계식을 통해 10개의 class score를 예측한다.
만약 고양이라는 클래스에 높은 score가 나왔다면 그것은 X가 고양이일 확률이 높다는 것을 의미한다.
위의 슬라이드처럼 이미지가 입력으로 들어올 때,
10개 class score를 예측하는 모델 f(x, W) = WX + b를 만들고자 한다면 f(x, W)는 10x1의 값을 가질 것이다.
또한 입력값인 고양이 이미지 한장은 3072개의 수로 이뤄졌기 때문에 x는 3072x1의 shape을 띤다.
따라서 이 모델에서 W는 식을 만족하기 위해 10x3072의 shape을 가지며,
따로 더해지는 bias는 10x1의 shape을 가진다.
Linear Classifier에서 가중치 행렬의 각 행은 각 class에 대한 template이라고 해석할 수 있다.
아래 슬라이드의 하단 그림들은 가중치 행렬의 각 행을 시각화한 것이다.

Linear Classifier는 아래의 경우 여전히 문제를 안고 있다.
- Linear한 boundary만 그릴 수 있다.
- boundary가 linear하지 않은 경우, 잘 동작하지 않는다.
- 데이터가 몇 개의 점처럼 나타날 경우 잘 동작하지 않는다.

'기술 > 딥러닝' 카테고리의 다른 글
| [Boostcamp AI Tech] Optimization (0) | 2021.08.11 |
|---|---|
| [Boostcamp AI Tech] Historical Review of Deep Learning (0) | 2021.08.09 |
| [Boostcamp AI Tech] 1주차 학습정리 (1) | 2021.08.06 |
| [Deep Learning] CNN for Deep Learning (2) | 2021.06.30 |
| [Deep Learning] Deep Learning Interview (1) | 2021.06.29 |

